
PgBouncer 도입 배경
PgBouncer는 PostgreSQL에 사용되는 커넥션 풀링 도구입니다.
PostgreSQL 서버와의 커넥션을 맺는 과정은 많은 자원을 소모하기 때문에, 한 번 만들어 둔 커넥션을 재사용할 필요가 있습니다. 이때 사용하는 것이 커넥션 풀링 도구입니다.
풀링을 사용하는 것만으로도 서버의 부하를 많이 낮출 수 있기 때문에, DB를 사용하는 경우에는 반드시 고려하는 것이 좋습니다.
각 언어별로 DB와 연결을 도와주는 라이브러리(ex: Python asyncpg)를 사용해 서버에서도 커넥션 풀링을 사용할 수 있지만, 쿠버네티스 오토스케일링 환경에서 서버를 운영 중이라면 PgBouncer 도입을 고려해볼 만합니다.
아래는 제가 회사에서 PgBouncer를 도입하게 된 계기입니다.
- 비용 절감을 위해서 서버의 리소스와 개수를 최적화하는 작업을 진행
- 서버 개수를 줄이다 보니, 서버별 커넥션 풀 사이즈를 더 큰 값으로 변경
- 피크 타임에 각 서버당 너무 많은 커넥션을 가지게 되어 DB 부하 (freeable memory 부족)
서버의 리소스 및 개수를 조절하는데 커넥션 풀까지 고려하다 보니, deadlock 같은 상황이 발생했고 중앙에서 커넥션 풀을 관리해줄 도구가 필요했습니다.
PgBouncer가 아니더라도 pgcat, supavisor 같은 후보도 있었습니다.
하지만, PgBouncer도 참고할 레퍼런스가 부족하다고 느꼈는데 다른 오픈소스들은 더 부족했기 때문에 세팅에 어려움을 겪을 것 같아 PgBouncer를 사용하게 되었습니다.
Connection Life Cycle
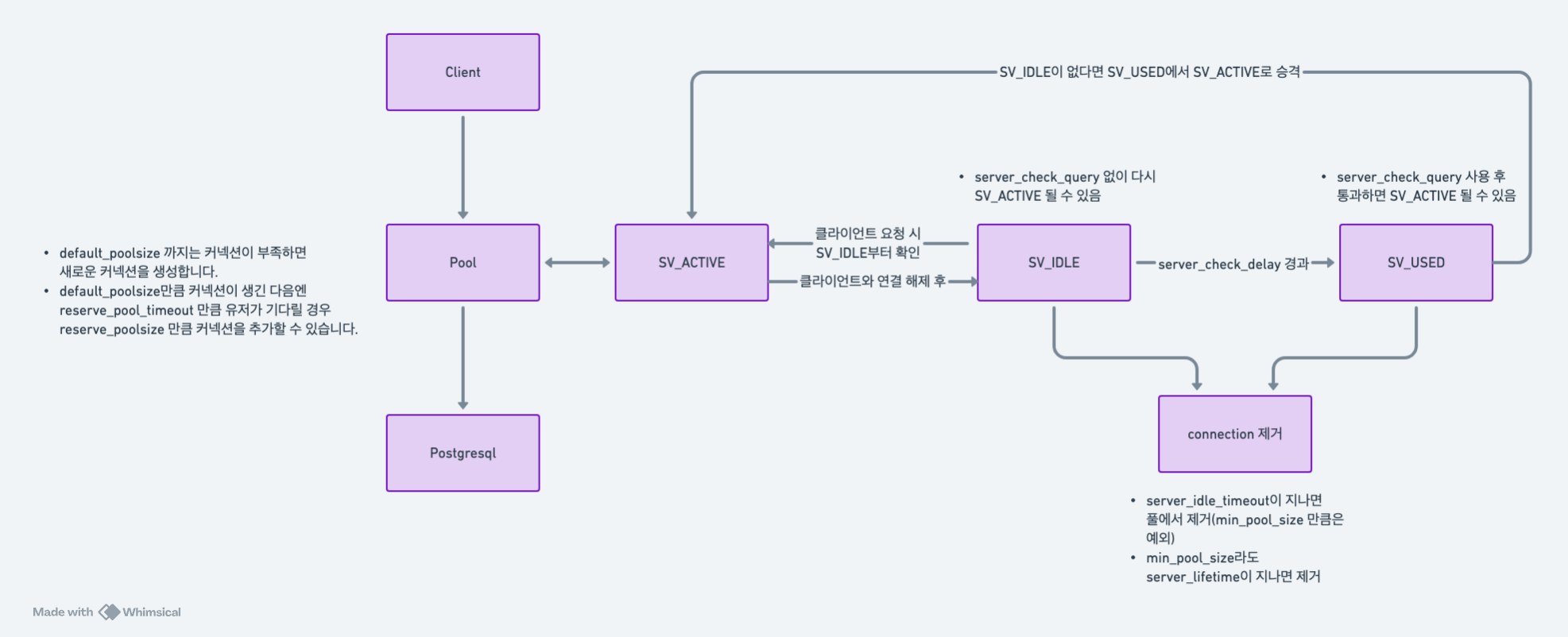
적절한 옵션값을 세팅하기 위해서는 PgBouncer의 커넥션 life cycle을 살펴봐야 합니다.
PgBouncer는 클라이언트의 요청에 따라 커넥션을 관리하며, 이 과정에서 SV_ACTIVE, SV_IDLE, SV_USED와 같은 상태로 커넥션이 변화합니다.
- 클라이언트 요청 시:
- PgBouncer는 새로운 커넥션을 생성하고, 이를 SV_ACTIVE 상태로 변경해 쿼리를 실행합니다.
- 클라이언트와의 연결이 끊어지면:
- 커넥션은 SV_IDLE 상태로 들어갑니다.
- 새로운 클라이언트 요청 시:
- SV_IDLE 상태의 커넥션은 별도의 server_check_query 없이 즉시 SV_ACTIVE 상태로 전환되어 쿼리를 실행합니다.
- SV_IDLE 상태에서 대기 시간 경과:
- SV_IDLE 상태에서 server_check_delay 만큼 시간이 지나면 커넥션은 SV_USED 상태로 전환됩니다.
- SV_IDLE 커넥션이 모두 사용 중일 때:
- 만약 SV_IDLE 상태의 커넥션이 없을 경우, SV_USED 상태의 커넥션을 가져와 사용하게 됩니다.이 경우 server_check_query를 실행해야 하므로 SV_IDLE 상태보다 시간이 더 걸릴 수 있습니다.
- 커넥션 제거:
- SV_IDLE 또는 SV_USED 상태에서 server_idle_timeout이 지나면, 커넥션은 PostgreSQL과 연결이 끊기고 풀에서 제거됩니다.
- 단 min_pool_size 만큼의 커넥션은 server_idle_timeout과 무관하게 유지되다가, server_lifetime이 지나면 제거됩니다.
아래는 PgBouncer 주요 설정들입니다.
- default_pool_size: 커넥션 풀에서 기본적으로 관리할 수 있는 최대 연결 수.
- min_pool_size: 오래 유지되는 최소 커넥션 수 (단, server_lifetime이 지나면 해당 커넥션도 종료됨).
- min_pool_size의 기본값은 0이기 때문에 따로 설정하지 않으면 PgBouncer를 반쪽으로 사용하게 됩니다. default_pool_size 설정만으로는 커넥션을 오래 유지할 수 없습니다.
- reserve_pool_size: 기본 커넥션 풀이 가득 찼을 때 추가로 생성할 수 있는 연결 수.
- 트래픽이 피크일 때, 추가적으로 reserve_pool_size를 활용하여 커넥션 풀을 더 확장할 수 있습니다. 다만, 이 커넥션은 reserve_pool_timeout 동안 대기한 후에야 생성됩니다.
- reserve_pool_size의 커넥션도 default_pool_size와 동일한 life cycle을 따릅니다.
- reserve_pool_timeout: 설정한 시간 동안 커넥션이 할당되지 않으면 새로운 연결이 생성됩니다.
- server_check_delay: server_check_query 없이 커넥션을 재사용할 수 있는 시간.
- 클라이언트와 연결이 끊긴 후 SV_IDLE 상태로 머무는 시간입니다.
- server_idle_timeout: SV_IDLE 또는 SV_USED 상태에서 연결이 자동으로 해지되는 시간.
- 단, min_pool_size만큼의 커넥션은 유지됩니다.
- server_lifetime: 연결이 유지될 수 있는 최대 시간.
- min_pool_size와 관계없이 시간이 지나면 연결이 해지됩니다.
transaction vs session
풀링모드의 트랜잭션과 세션에는 어떤 차이가 있을까요?
session: Server is released back to pool after client disconnects.
transaction: Server is released back to pool after transaction finishes.
공식문서를 확인하면 session은 client와 disconnect됐을 때 풀에 커넥션을 반환하고, transaction은 트랜잭션이 끝나는 commit과 rollback 마다 커넥션을 풀에 반환하다고 적혀있습니다.
sqlalchemy+asyncpg 를 쓰는 상황에서는 어떻게 되는지 좀 더 자세히 알아보겠습니다.
if use_nullpool:
engine = create_async_engine(dsn, poolclass=NullPool)
else:
engine = create_async_engine(dsn, pool_size=5, max_overflow=10)
session_factory = async_scoped_session(
async_sessionmaker(
autoflush=False,
expire_on_commit=False,
class_=AsyncSession,
bind=engine,
),
scopefunc=asyncio.current_task,
)
async with engine.connect() as conn:
print("sleep 10 before first query")
await asyncio.sleep(10)
await conn.execute(sa.text("SELECT 1"))
await conn.commit()
print("execute first query and commit")
print("sleep 10 before second query")
await asyncio.sleep(10)
await conn.execute(sa.text("SELECT 1"))
print("execute second query and not commit")
await asyncio.sleep(10)
print("sleep 10 before first query")
await asyncio.sleep(10)
await session.execute(sa.text("SELECT 1"))
await session.commit()
print("execute first query and commit")
print("sleep 10 before second query")
await asyncio.sleep(10)
await session.execute(sa.text("SELECT 1"))
print("execute second query and not commit")
await asyncio.sleep(10)
pgbouncer를 세팅 후 위 스크립트를 실행 한 다음 sleep 걸렸을 때마다 아래 커맨드를 사용해 지표를 확인했습니다.
psql -h localhost -p 6432 -U user pgbouncer -c 'SHOW POOLS;'
NullPool을 사용하는 경우와 사용하지 않는경우, engine을 사용하는 경우와 세션팩토리를 사용하는 경우로 나누어서 보겠습니다.
session + NullPool + engine
- engine connect 컨텍스트가 열려있을 때는 항상 sv_active가 1로 유지됩니다.
- 컨텍스트가 닫히면 sv_active가 0이 되고 sv_idle이 1이 됩니다.
- commit과 관련없이 컨텍스트가 열려있으면 커넥션을 항상 서버가 점유하게 됩니다. 단, 컨텍스트가 닫히면 NullPool이기 때문에 서버가 커넥션을 pgbouncer에 반환합니다.
session + Pool + engine
- NullPool 일 때 와 다르게 컨텍스트가 끝나고 서버가 커넥션을 점유하게 됩니다.
transaction 모드
- context manager와 관게없이 execute시에 connection을 획득하게 되며 commit 또는 rollback 시에 커넥션을 pgbouncer에 반환합니다.
- NullPool, Pool 관계없이 똑같이 동작합니다.
session을 사용하게 되는 경우 commit마다 컨텍스트가 닫히는 것과 똑같기 때문에 위 결과랑 차이가 없습니다.
그렇다면 오토스케일링 되는 비동기 웹서버에서는 어떤 방식을 사용해야 할까요?
레퍼런스가 부족해 best practice나 real-world 예제를 찾지는 못했지만
제 생각엔, NullPool + transaction 모드를 사용해야 할 것 같습니다. 당연히 프로젝트 구성마다 다르겠지만 저희는 요청마다 한개의 트랜잭션을 사용하는것을 기본으로 하고 있어서 session을 사용할 이유가 없었습니다.
session을 사용하는 이유는 커넥션을 서버가 오래 점유하면서 prepared_statement나 query cache에서 이점을 얻는 것인데
Pool을 사용해서 서버가 커넥션을 오래점유 할 것 이라면 asyncpg로 충분할 것이고
pgboncer에 반환할 것이라면 session을 transaction처럼 쓰게 되는 상황이 발생하기 때문에 transaction 모드를 사용하면 될 것 같습니다.
prepared_statements
pgbouncer를 transaction 모드로 사용하면 prepared_statement를 사용할 수 없어서 prepared_statement_cache_size를 0으로 설정해주어야 합니다. (sqlalchemy 이슈를 참고해서 사용했습니다.)
from uuid import uuid4
from asyncpg import Connection
from sqlalchemy.ext.asyncio import create_async_engine
from sqlalchemy.pool import NullPool
class CConnection(Connection):
def _get_unique_id(self, prefix: str) -> str:
return f"__asyncpg_{prefix}_{uuid4()}__"
engine = create_async_engine(
db_url,
poolclass=NullPool,
connect_args={
"statement_cache_size": 0,
"prepared_statement_cache_size": 0,
"connection_class": CConnection,
},
)
하지만 ORM을 사용하는경우 데이터베이스 컬럼 타입과 프로그래밍 언어의 타입을 매핑하기 위해서 pg_type 테이블에 대한 쿼리가 발생하고 이를 prepared_statement로 캐싱해두는데, prepared_statement의 cache size를 0으로 설정하면 pg_type 쿼리에 대한 부하가 심해질 수 있습니다.
다행히 PR이 병합된 후 부터 transcation 모드에서도 max_prepared_statements를 통해서 prepared_statement를 사용할 수 있게 되었습니다.
max_prepared_statements 옵션을 사용하게 되면 cache_size를 0으로 지정했던 설정을 제거해야 prepard_statement를 사용할 수 있게 됩니다.
engine = create_async_engine(
db_url,
poolclass=NullPool,
)
옵션에 대한 설명을 읽어보면 client에서 지정한 prepared_statement 이름을 pgbouncer가 다른 이름으로 맵핑해서 메모리에 갖고 있게 되는 것 같습니다.
따라서 pgbouncer 리소스와 연관이 있으니 설정 후 리소스 사용량을 확인하시는게 좋을 것 같습니다.
기타
- PgBouncer 데이터베이스를 설정할 때 유저, 비밀번호, DB명을 명시하지 않으면 클라이언트 측에서 PgBouncer에 접속할 때 사용한 정보를 그대로 사용합니다.
- client → postgresql://foo@pgbouncer/zoo → PgBouncer → postgresql://foo@postgresql-host/zoo → PostgreSQL
- 단, PostgreSQL의 유저 및 비밀번호를 기반으로 PgBouncer의 userlist를 설정해야 합니다.
아쉬운 점
읽기/쓰기 쿼리 자동 라우팅 기능이 없다는 것이 아쉬웠습니다. 이 때문에 읽기 복제본을 운영하는 입장에서 PgBouncer 데이터베이스에 write와 readonly를 따로 설정해줘야 하는 불편함이 있었습니다.